Welcome to SciClaimEval, a pilot task on the verification of scientific claims against tables and figures from scientific articles. The task is organized as part of NTCIR-19 and aims to evaluate systems that can reliably check the truthfulness of scientific statements using multi-modal evidence.
Scientific claim verification involves determining whether claims made in research papers are supported or refuted by accompanying evidence, such as experimental results, tables, and figures. With the rapid rise of generative AI and large language models (LLMs), the volume of scientific submissions has increased substantially, creating a growing demand for tools that can assist reviewers in assessing the validity and consistency of paper claims.
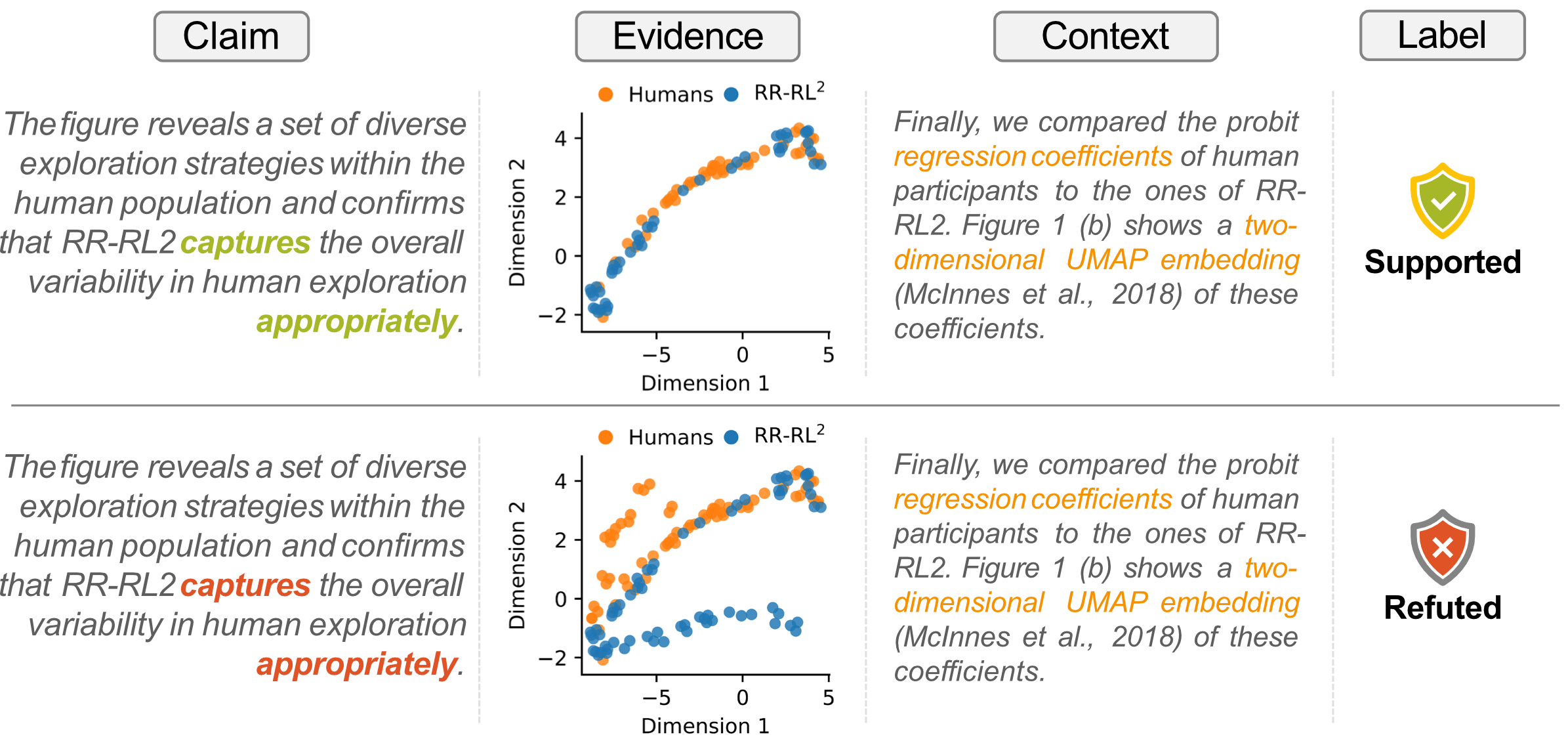
The SciClaimEval pilot task focuses on cross-modal scientific claim verification, aiming to assess whether textual claims in scientific papers are adequately supported by evidence from diverse modalities, namely tables and figures. We introduce a new benchmark dataset, constructed by extracting claims and their corresponding evidence from scientific articles across multiple domains, including biomedicine, machine learning, and natural language processing. The figure below illustrates an example from the benchmark dataset. The task involves determining whether a claim is supported or refuted given a piece of evidence (a table or a figure) and optional contextual information (preceding text in the original paragraph).
Synopsis
- Register as participant by June 1, 2026
- Submit your run on the test dataset by July 19, 2026
- Submit your paper draft by September 1, 2026
Task Description
- Development Dataset: huggingface.co/datasets/alabnii/sciclaimeval-shared-task
- Formal Run Dataset: huggingface.co/datasets/alabnii/sciclaimeval-shared-task-test
- Evaluation scripts & examples: github.com/SciClaimEval/sciclaimeval-shared-task
The task dataset will be published in three rounds. First, we publish a development dataset (dev set) in order to let everyone explore parts of the data on January 31. Second, the formal test dataset will be released only for task participants in March. Participants are required to submit their results on this formal run dataset! Following the NTCIR conference, we make all data subsequently publicly available by the end of 2026.
This task includes two subtasks. Participants can submit solutions to either or both subtasks.
Dataset
The data consists of JSON files of all claims alongside figures (PNG), tables (PNG), and the full paper texts (JSON).
Each claim contains a unique path to an evidence file (evi_path for subtask 1 or evidence_id_1/evidence_id_2 for subtask 2) and evi_type that indicates the type of evidence (either table or figure).
Additionally, we provide contextual information, including the caption (caption), immediate context of the claim (context), and a path to the full paper content (paper_path). The use_context field indicates whether additional context is necessary to potentially disambiguate the claim. Specifically, use_context contains either no (no additional context required), yes (requires the context field for disambiguation), or other sources (requires the full paper for disambiguation).
Optional: For tables, we provide access to the original source format of the table (LaTeX or HTML). Participants are allowed to additionally submit results for subtask 1 on these formats besides the mandatory PNG formats. evi_path_original can be used as a unique path to the original variant.
Subtask 1: Claim Label Prediction Task
In this subtask, you predict if a given claim (text) is either Supported or Refuted by the given evidence (tables and figures in PNG format).
Prediction Format: All participants of subtask 1 are required to submit a results file in this format. The claim_id matches the claim_id in the data. The pred_label (prediction label) contains either Supported or Refuted. If your solution produces a confidence score for the prediction, you can add the optional score field to the submission. Any other fields will be ignored. A submission on other formats (see optional description above) will be distinguished in the submission form and not the result format.
[
{
"claim_id": "val_tab_0001",
"pred_label": "Refuted"
}
]
Test Format: Example of a test entry for subtask 1.
[
{
"paper_id": "2403.19137",
"claim_id": "val_tab_0001",
"claim": "Table 1 shows that our probabilistic inference module consistently outperforms its deterministic counterpart in terms of Avg and Last accuracy.",
"caption": "Table 1 : Performance comparison of different methods averaged over three runs. Best scores are in bold . Second best scores are in blue . The results for L2P, DualPrompt, and PROOF are taken from [ 92 ] . See App. Table 14 for std. dev. scores.",
"evi_type": "table",
"evi_path": "tables_png/dev/val_tab_0001.png",
"evi_path_original": "tables/dev/val_tab_0001.tex",
"context": "To understand our probabilistic inference modules further, we examine their performance against the deterministic variant of ours (Ours w/o VI).",
"domain": "ml",
"use_context": "yes",
"paper_path": "papers/dev/ml_2403.19137.json",
"license_name": "CC BY 4.0",
"license_url": "http://creativecommons.org/licenses/by/4.0/"
}
]
Subtask 2: Claim Evidence Prediction Task
In this subtask, you predict which of the two given pieces of evidence (tables and figures) supports the claim (text).
Prediction Format: All participants of subtask 2 are required to submit a results file in this format. The sample_id matches the sample_id in the data. The pred_label (prediction label) contains either evidence_id_1 or evidence_id_2 depending on which evidence supports the claim. As for subtask 1, participants can provide an additional score flag to indicate the model’s confidence.
[
{
"sample_id": "val_0071",
"pred_label": "evidence_id_1"
}
]
Test Format: Example of a test entry for subtask 2.
[
{
"sample_id": "val_0071",
"evidence_id_1": "figures/dev/val_fig_0113.png",
"evidence_id_2": "figures/dev/val_fig_0114.png",
"claim": "As shown in Figure 4(b) , increasing the value of \\alpha can prevent the model from outputting more sensitive information, but it may also lead to the loss of necessary information.",
"context": "For unlearning, we found that adjusting the value of \\alpha can serve as a balance between forgetting and retaining .",
"caption": "(a) Impact on instruction tuning; (b) Impact on unlearning; Impact of strength coefficient \\alpha on performance",
"domain": "ml",
"evi_type": "figure",
"paper_id": "2410.17599",
"use_context": "other sources",
"paper_path": "papers/dev/ml_2410.17599.json",
"license_name": "CC BY 4.0",
"license_url": "http://creativecommons.org/licenses/by/4.0/"
}
]
Evaluations & Baselines
The evaluation script (in python) is available on github: github.com/SciClaimEval/sciclaimeval-shared-task.
All submissions will be evaluated on precision, recall, macro F1, and accuracy. In order to minimize the risk of model bias on subtask 1, the primary evaluation metric here is accuracy on claim pairs (a claim pair are two entries in the dataset with the same claim but opposing evidence labels). This stricter metric only counts correct results if both entries of a pair were correctly predicted (i.e., the supported claim and refuted claim of the same claim text were correctly identified).
| Subtask 1 Baselines | Precision | Recall | Macro-F1 | Accuracy | Pair Accuracy |
|---|---|---|---|---|---|
| o4-mini | 83.4 | 82.4 | 82.9 | 82.3 | 68.2 |
| Qwen3-VL-30B-A3B | 77.1 | 74.8 | 76.0 | 75.0 | 54.8 |
| Qwen3-VL-8B | 76.3 | 68.3 | 72.1 | 68.3 | 46.9 |
| InternVL3_5-38B | 72.1 | 68.1 | 67.8 | 69.2 | 40.1 |
| Llama-3.2-11B-Vision | 57.4 | 52.9 | 48.6 | 54.8 | 10.8 |
| Subtask 2 Baselines | Precision | Recall | Macro-F1 |
|---|---|---|---|
| tba. | - | - | - |
News
- [2026-03-02] The test dataset is now available on huggingface: alabnii/sciclaimeval-shared-task-test.
- [2026-02-07] We published a paper explaining the task at LREC 2026. The pre-print is available on arXiv: SciClaimEval: Cross-modal Claim Verification in Scientific Papers
- [2026-01-31] The development dataset is now available on huggingface: alabnii/sciclaimeval-shared-task.
- [2026-01-26] Participation registration for SciClaimEval is now available.
Important Dates
| Date | Event |
|---|---|
| January 31, 2026 | Development Dataset Release |
| March 01, 2026 | Formal Run Dataset Release |
| June 1, 2026 | Registration Deadline for Participants |
| July 19, 2026 | Formal Run Submission Deadline |
| August 1, 2026 | Evaluation Results Return |
| September 1, 2026 | Submission Due for Participant’s Papers |
| November 1, 2026 | Camera-ready participant paper due |
| December 8 - 10, 2026 | NTCIR-19 Conference |
| December 11, 2026 | Full Dataset Release |
All deadlines are 11.59 pm UTC -12h (Anywhere on Earth (AoE)).
Registration for Participation
To participate in the SciClaimEval task, participants must (1) register via the 19th NTCIR online registration system and (2) submit a signed memorandum.
Contact
Please direct any questions or corrections regarding the task to: sciclaimeval (at) gmail.com
Cite Us
To cite this work, please use the following BibTeX. We will update the URL and page numbers once the official LREC 2026 proceedings are released.
@InProceedings{HoWKXBGA2026,
title = "{S}ci{C}laim{E}val: Cross-modal Claim Verification in Scientific Papers",
author = "Xanh Ho and Yun-Ang Wu and Sunisth Kumar and Tian Cheng Xia and Florian Boudin and Andre Greiner-Petter and Akiko Aizawa",
booktitle = "Proceedings of the 15th Language Resources and Evaluation Conference (LREC 2026)",
month = may,
year = "2026",
address = "Palma de Mallorca, Spain",
publisher = "ELRA Language Resources Association",
url = "https://arxiv.org/abs/2602.07621"
}
Organizers
- Akiko Aizawa (National Institute of Informatics, Japan)
- André Greiner-Petter (University of Göttingen, Germany)
- Florian Boudin (Inria, France)
- Xanh Ho (National Institute of Informatics, Japan)